In the TwinLife study, participants were asked to provide saliva samples up to three times. The initial saliva collection took place shortly before the SARS-CoV-2 pandemic (2018–2020) during F2F3. The saliva samples were collected with the help of trained interviewers in the participants’ households. In F2F4a and CATI 3b (2020-21), participants were asked to provide consent for a second saliva sample, which was subsequently collected during the Cov3 wave (2021). Due to the COVID pandemic-related contact restrictions, these saliva samples were collected via collection kits sent by mail. The participants were given extensive written instructions to conduct the sampling themselves and return the samples via mail. Finally, during F2F5 (2022-2024), a third saliva sample was collected (or a second or first sample, according to prior participation).
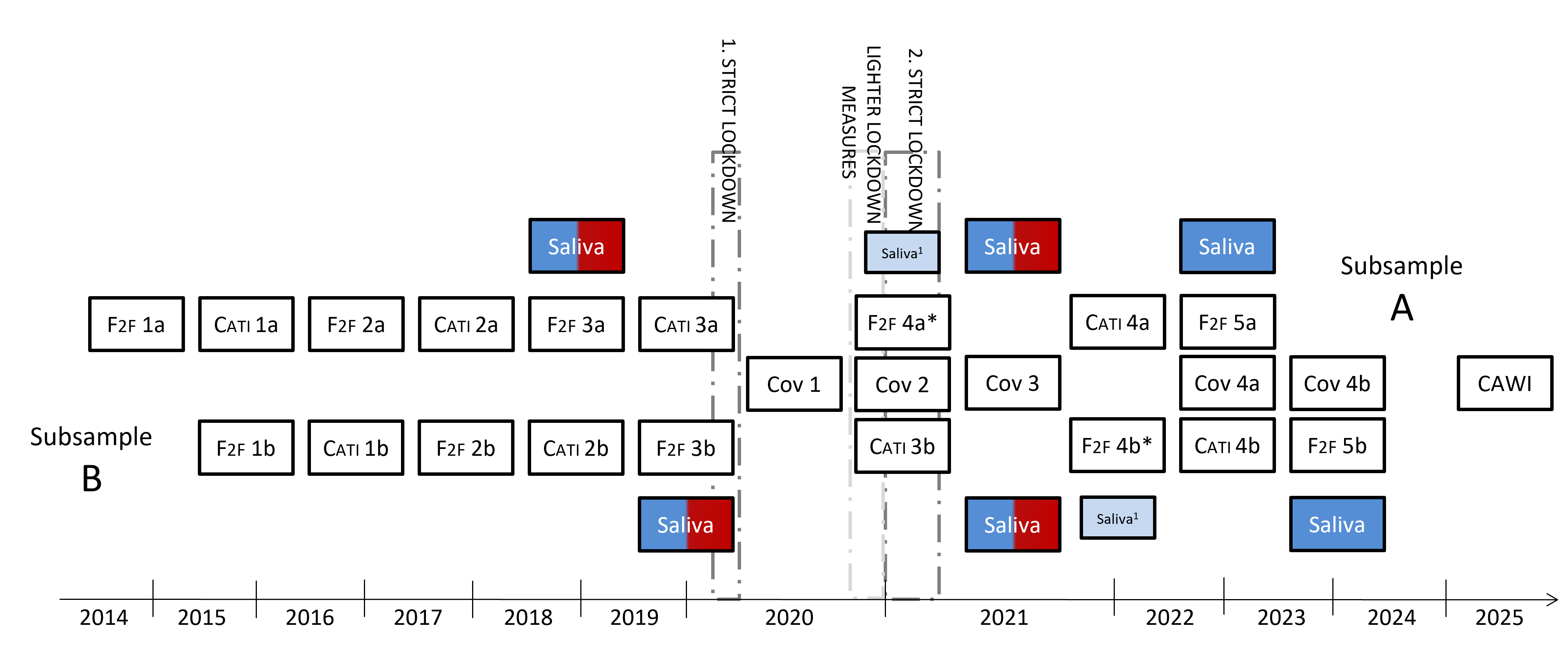
Figure. Overview of the time points when saliva samples were collected in the TwinLife study. Additional red coloring indicates that - for this time point - epigenetic information is available. 1 only follow-up collection of the first saliva sample.
Prior to each sampling, the participants received extensive information about the scope of the study, how their saliva will be processed and used for research, the data protection regulations, and the participants’ rights. Participants were asked to give written informed consent. Additionally, if a participant was underage, the legal guardian had to provide consent. Saliva collection and subsequent processing were also part of the TwinSNPs and TECS projects.
Genetic Data
For a detailed description of DNA extraction and processing procedures, see Frach et al., 2026. All procedures were approved by the Ethics Committee of the Medical Faculty of the University of Bonn, Germany (Lfd. 113/18).
DNA extraction, genotyping, and further data processing were performed at the Institute of Human Genetics and the Institute for Genomic Statistics and Bioinformatics, University of Bonn. Customized Illumina Global Screening Arrays were used, incorporating additional markers relevant to psychiatric disorders. After quality control, including filtering for common and well-measured variants, imputation of unmeasured variants, and checking for plausibility, data from currently 5,421 individuals (as of January 2026) met the quality standards (1,213 complete twin pairs, 292 additional twins, 522 siblings, 917 fathers and 1,263 mothers).
Participants were excluded from further analyses if they presented (a) a sex mismatch, (b) a family mismatch, c) insufficient DNA quality or (d) a principal component outlier. Additionally, data is restricted to individuals with inferred European ancestry. When using PGS data, scores are typically residualized for a number of genetic principal components (which are derived through principal component analysis and capture variances associated with genetic stratification and ancestry). PGS can be used similarly to any other predictor in statistical models. For an extensive introduction on working with polygenic scores, please see:
Allegrini, A. G., Baldwin, J. R., Barkhuizen, W., & Pingault, J.-B. (2022). Research Review: A guide to computing and implementing polygenic scores in developmental research. Journal of Child Psychology and Psychiatry, 63(10), 1111–1124. https://doi.org/10.1111/jcpp.13611
Pingault, J.-B., Allegrini, A. G., Odigie, T., Frach, L., Baldwin, J. R., Rijsdijk, F., & Dudbridge, F. (2022). Research Review: How to interpret associations between polygenic scores, environmental risks, and phenotypes. Journal of Child Psychology and Psychiatry, 63(10), 1125–1139. https://doi.org/10.1111/jcpp.13607
Numerous polygenic scores (PGS) were calculated based on summary statistics from genome-wide association studies, serving as proxies for genetic predispositions related to specific traits. A list of available PGS can be found in the ➔ Downloads section.
Epigenetic Data
The sample for the epigenetic satellite project (TECS) was selected after the first saliva sample had been collected and processed, with a focus on the twin pairs. Because monozygotic twins share all their genetic make-up, and dizygotic twins share on average half of it, epigenetic differences can be investigated in relation to environmental variation. To be selected for epigenetic assessment (i.e., DNA methylation), a twin pair needed to a) have provided two valid saliva samples for each twin (collected at F2F3 and Cov3, see figure), and b) have valid phenotypic data for Cov3.
The DNA was extracted at the Institute of Human Genetics, University of Bonn. For a detailed description of extraction and processing procedures, see Frach et al., 2026. Preprocessing, quality control and the aggregation of epigenetic data to epigenetic composites were executed at the Max-Planck Institute of Psychiatry in Munich. For further information, please also refer to Frach et al., 2026. As of January 2026, epigenetic data is available for 1,055 participants (489 of which were complete twin pairs, while 250 of these were monozygotic).
The epigenetic data includes DNA methylation of approximately 700,000 individual genomic sites. Moreover, analogous to PGS, several aggregates can be built using epigenetic data. A prominent example of epigenetic aggregates are epigenetic clocks that reflect “biological tissue aging”. When biologically inferred age is set into relation to chronological age, age acceleration or deceleration can be estimated (having aged faster or slower biologically than expected by the passage of time). Usually, these scores are controlled for cell type, BMI and smoking, as these variables have been shown to contribute heavily to age acceleration. Other epigenetic aggregates are also commonly used in literature (e.g. epigenetic g, inflammatory markers). A list of all available composite scores for the TwinLife study can be found in the ➔ Downloads section.
If you wish to work with our molecular genetic and epigenetic data, please fill out the research proposal form and send it to us via email to
Please make sure that your proposal is in line with ethical standards and is within the broad scope of the TwinLife study (studying underlying mechanisms of social inequality). After reviewing the proposal by the TwinLife study board, researchers are invited to a meeting to discuss the research proposal and to plan the next steps. For data access, a formal contract is necessary. Data access can only be granted after the formal contract has been approved by the administrations of the institutions involved. Please understand that these processes can take some time.